


Définition du Web Scraping
Le Web Scraping est une technologie permettant de récupérer de manière automatisée des données provenant de diverses pages Internet.
Le Scraper, quant à lui, désigne le programme (script, robot, etc) qui récupère les informations souhaitées sur les pages Internet.
Il permet d’extraire des données et des informations présentées sur ces sites web de manière systématisée et de les transformer en d’autres formats plus exploitables (Excel, CSV, etc).
Intérêts
Le Web Scraping possède de multiples intérêts :
- En marketing, car de nombreuses informations pertinentes concernant les stratégies commerciales de concurrents sont disponibles sur Internet. Récupérer ces informations de manière systématique permet alors d’optimiser le positionnement du prix d’un produit, d’optimiser sa disponibilité, etc.
- Analyser les retours et avis des clients sur divers sites de commerces, réseaux sociaux, etc, et en faire de l’analyse de sentiment pour se faire une idée quant à la qualité d’un produit ou d’un service
- Les comparateurs en ligne reposent avant tout sur cette technologie.
- Pour les ressources humaines, en « scrapant » divers job board
Prérequis
De part la nature même de cette technologie, des connaissances basiques en HTML et CSS sont nécessaires. Pour le développement même d’un scraper, des notions de Python sont également requises.
Que dit la législation à ce propos ?
Le web scraping peut parfois être utilisé à mauvais escient malheureusement : récupération de données personnelles, abus de requêtes mettant hors service un site web, etc… De ce fait, de nombreux sites tentent de s’en prémunir.
Les informations concernant le scraping sont mentionnées dans les CGU (Conditions Générales d’Utilisation). Même si cela est proscrit par certains sites, la récupération automatisée d’informations qui sont en libre accès (par exemple sans inscription) restent tout à fait légale, tant qu’elles ne sont pas destinées à la revente.
Il faut toutefois faire attention à ne pas effectuer des requêtes trop nombreuses, cela pouvant simplement mettre hors service un site web (c’est ni plus ni moins qu’une attaque par déni de service distribué (DDOS).
Cependant, des outils existent pour les développeurs web visant à limiter cette pratique. Les plus connues sont :
- reCaptcha : dont le but est d’empêcher les robots d’accéder à la page située derrière le Captcha.
- robot.txt : il s’agit d’un fichier à la racine de certains site web interdisant les robots d’accéder à certaines pages. Par exemple ici : https://www.imdb.com/robots.txt.
En pratique
Pour finir, nous allons développer un petit robot de scraping assez simple, dont le but sera d’aller récupérer les offres d’emplois de chef de projet disponibles sur le site www.hellowork.com, avec l’entreprise qui recrute et le salaire proposé (s’il est disponible).
On pourrait très bien également ne récupérer les infos que pour une zone donnée, selon certains autres critères, etc.
Si cette partie ne vous intéresse pas, rendez-vous directement au chapitre conclusion.
Avant toute chose, il faut identifier la page web « cible ».
Dans le cadre de notre exemple, ce seront les résultats de la requête suivante : https://www.hellowork.com/fr-fr/emploi/recherche.html?k=chef+de+projet&ray=all&d=all&p=1
Cette page a été obtenue simplement en recherchant le terme « chef de projet » dans le champ adéquat. On va garder cette page de côté, et nous y reviendront dans un moment pour identifier les éléments que l’on souhaite récupérer.
Note : On remarque sur le site que tous les résultats ne sont pas affichés (il y a plusieurs pages de résultats). La notion de pagination ne sera pas abordée ici, car nécessite des notions plus avancées en Python. Sachez néanmoins que c’est bien évidement faisable.
Après avoir ouvert votre éditeur Python préféré, il faut importer les bibliothèques nécessaires
| from urllib.request import urlopen from bs4 import BeautifulSoup import pandas as pd | # Utilisé pour accéder à un lien web # Bibliothèque de web scraping # Nous servira ici à former une petite base de données en csv |
Ensuite, nous allons simplement initialiser la page cible, et le package de scraping.
| # URL Ciblée url = ‘https://www.hellowork.com/fr-fr/emploi/recherche.html?k=chef+de+projet&ray=all&d=all&p=1’ page_hw = urlopen(url) # Initialisiation de BeautifulSoup soup = BeautifulSoup(page_hw, ‘html.parser’) |
A présent, il nous faut identifier les éléments à récupérer sur le site web. Pour cela, rendez-vous sur votre navigateur, et sur la page web, effectuez un clic droit, puis « Inspecter » (l’option peut se trouver à différents endroits selon votre navigateur).

Ensuite, le plus simple est d’utiliser le « DOM inspector », il s’agit de l’icone située en haut à gauche du volet développeur :

Avec cet outil on peut à présent sélectionner n’importe quel objet de la page web.
On va commencer par le titre :


On voit dans le menu développeur l’identification complète du titre. Il s’agit d’un lien hypertexte (balise <a> … </a>). La class de ce lien contient plusieurs éléments. Celui dont on va se servir sera tw-leading-[1.625rem] (on aurait très bien pu en prendre un autre). Ok, notons cela dans un coin, et continuons.
On veut à présent la société émettrice de l’offre d’emploi. Même procédure ici :

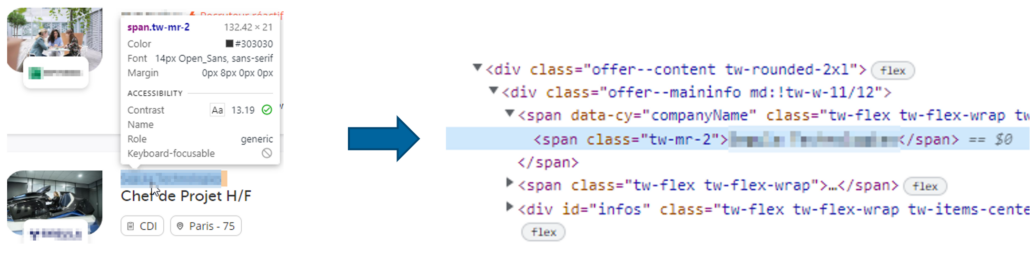
Petite différence cependant, il ne s’agit plus d’un lien, mais d’une balise span. Le procédé reste identique, récupérons donc la classe : tw-mr-2.
Et pareil pour le salaire : tw-text-tertiary.
Continuons sur notre petit robot Python.
Afin de récupérer les informations des titres, il faut procéder ainsi :
| names = soup.findAll(name=’a’, attrs={‘class’: ‘tw-leading-[1.625rem]’}) |
- Via notre package bs4 initialisé précédemment, on utilise la méthode findAll qui va nous retourner une liste d’objets
- La valeur name= correspond à la balise (ici une balise de lien, a).
- La valeur de attrs= attend un dictionnaire (correspondance clé : valeur). Dans notre cas, il faut comprendre : class ayant pour valeur tw-leading-[1.625rem].
Procédons de même pour les autres :
| companies = soup.findAll(name=‘span’, attrs={‘class’: ‘tw-mr-2’}) salaries = soup.findAll(name=‘span’, attrs={‘class’: ‘tw-text-tertiary’}) |
A présent, il est nécessaire d’initialiser des listes vides qui contiendront nos valeurs.
| hw_title = [] hw_company = [] hw_salaries = [] |
Itérons parmi tous nos résultats.
Comme précisé précédemment, BeautifulSoup nous retourne ici des listes. On procède de la manière suivante :
| for item in names: hw_title.append(item.text.replace(« \n », « »).strip()) for item in companies: hw_company.append(item.text.replace(« \n »,« »)) for item in salaries: hw_salaries.append(item.text) |
Petite explication :
- for item in names : boucle pour parcourir tous les résultats renvoyés par la variable « names » (donc tous les titres en somme).
- hw_title.append : Pour chaque élément trouvé, on ajoute uniquement le texte à la liste vide (si nous ne précisons pas item.text, il nous sera retourné l’intégralité de la balise http).
- Replace et strip : Il s’agit là de mise en forme principalement. On remplace (replace) tous les retours à la ligne (\n) et tous les espaces superflus (strip) par rien.
- Puis on fait la même chose sur les autres éléments.
Pour finir, nous allons exporter cela dans un fichier csv dans le but d’avoir des résultats exploitables.
| df = pd.DataFrame(list(zip(hw_title, hw_company, hw_salaries)), columns=[‘Title’, ‘Company’, ‘Salary’]) df.to_csv(‘/home/ubuntu/Documents/scraper.csv’) |
Nous n’allons pas nous attarder sur des explications ici. Il faut juste comprendre qu’on créé un dataframe (sorte de tableau évolué permettant des opérations complexes, principalement pour la gestion, la manipulation et la visualisation de données), et qu’on transforme ce Dataframe en fichier CSV.
Le csv généré est donc ainsi :


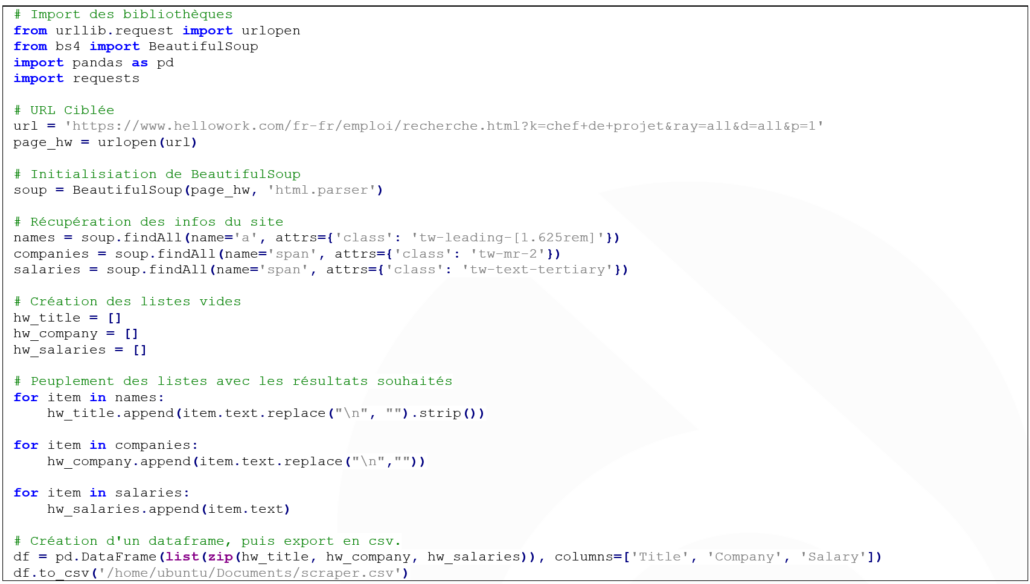
Voici le code complet du robot :

Conclusion
Vous l’aurez certainement remarqué, le web scraping est une puissante technologie de récupération automatisée de données issues de sites web (concurrents, job boards, et même de recherches web).
On peut bien évidemment aller beaucoup plus loin. Il s’agit là que d’une introduction pour mieux comprendre cette pratique.